爬取啥意思:爬取数据的基本原理
1、爬虫是一种按照既定规则,在网络上自动爬取信息的程序或脚本爬虫也被称为网页蜘蛛或网络机器人,可以自动抓取网络信息,主要用于网站数据采集内容监测等爬虫的工作原理是一个循环的过程,首先确定一些初始的网页链接URL作为爬取数据的入口接着,爬虫会发送请求到这些URL对应的服务器,下载对应的;方法步骤 在做爬取数据之前,你需要下载安装两个东西,一个是urllib,另外一个是pythondocx请点击输入图片描述 然后在python的编辑器中输入import选项,提供这两个库的服务 请点击输入图片描述 urllib主要负责抓取网页的数据,单纯的抓取网页数据其实很简单,输入如图所示的命令,后面带链接即可请点击;“爬”一词是近年来在网络上出现的一个流行词汇,它在不同场合下可能有不同的意义通常来说,爬指的是通过代码程序或技术手段从网站或服务端获取数据的过程,也就是“爬取数据”,如爬虫数据爬取等但是,在不同的上下文中,“爬”可能还有其他的含义,需要根据具体情境和语境理解爬取数据在;网络爬虫,也被称作网页蜘蛛网络机器人,在FOAF社区中更常被称作网页追逐者,是一种遵循特定规则,自动抓取万维网信息的程序或脚本此外,它还有一些不常用的称呼,如蚂蚁自动索引模拟程序或蠕虫网络爬虫是一个自动提取网页的程序,它负责从万维网上下载网页,是搜索引擎的核心组成部分传统爬虫从。
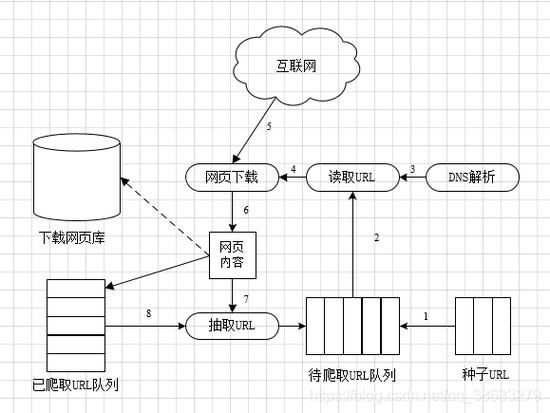
2、爬取数据是指使用程序自动化地从网页中提取数据的行为这通常是通过网络爬虫来完成的,网络爬虫会自动地遍历网页,识别和提取相应的信息,并将其生成结构化的数据集合存储在一定的文件格式中,如CSV或XML爬取数据可以帮助我们快速有效地获取大量数据无论是企业研究机构还是个人,只要有数据需求,爬;爬取数据的意思就是通过程序来获取需要的网站上的内容信息,如文字视频图片等数据以下是关于爬取数据的详细解释定义爬取数据通常涉及到使用网络爬虫这一技术网络爬虫是一种按照一定的规则,自动地抓取万维网信息的程序或脚本工作流程传统爬虫从一个或若干初始网页的URL开始,获取初始网页。
3、百度作为全球知名的搜索引擎,其运作机制依赖于一种被称为“爬虫”的技术爬虫是一种自动化程序,它能够沿着网页之间的链接不断探索,搜集网页内容并将其下载至本地服务器这种技术对于搜索引擎优化SEO至关重要,因为通过爬取网页内容,搜索引擎能够提供更加精准和全面的信息然而,这种大规模的数据;Python爬虫是使用Python程序开发的网络爬虫,是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本以下是关于Python爬虫的详细解释主要用途Python爬虫主要用于搜索引擎,通过爬取网站的内容与链接,建立全文索引到数据库中,以便用户进行搜索工作原理爬虫从一个或多个初始网页的URL开始,读取网页;所谓爬虫就是指在给定url网址中获取我们对我们有用的数据信息,通过代码实现数据的大量获取,在经过后期的数据整理计算等得出相关规律,以及行业趋势等信息Python 爬虫架构主要由五个部分组成,分别是调度器URL管理器网页下载器网页解析器应用程序爬取的有价值数据调度器相当于一台。
4、网站收录,在搜索引擎角度来讲也叫网站索引,被很多SEO称为网站收录,搜索引擎在爬取你的网页以后,通过对网页内容进行检测,如果内容符合收录规则,就将网页加入自己的索引库,当用户查询相关内容时,这个网页就会出现在搜索结果,所以百度收录是什么意思?就可以解释为百度爬取了你的网页,并认为你的网页。
5、爬小说是指使用网络爬虫技术,从小说网站上爬取小说内容网络爬虫是一种自动化程序,可以在网站上抓取信息并将其整理成机器可读的格式在小说网站上,爬虫程序可以自动访问小说的页面,将小说内容抓取下来并保存到本地或服务器上这种行为会对小说网站的服务器造成负担,也会侵犯小说版权,因此并不被网站;爬虫攻击指的是利用网络爬虫技术,将恶意代码嵌入到已知的爬虫程序中,通过对网站进行爬取,对其进行非法访问或数据采集,从而实现对网站的攻击和破坏爬虫攻击的目的通常是获取用户数据或者是窃取网站内部的商业机密信息等,这种攻击方式已经成为了当前网络攻击的主要形式之一爬虫攻击的危害主要表现在以下几个;爬取数据是指通过程序来获取需要的网站上的内容信息,比如文字视频图片等数据以下是关于爬取数据的详细解释定义与工具爬取数据主要依赖网络爬虫这一工具网络爬虫是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本工作流程传统爬虫从一个或若干初始网页的URL开始,获取初始网页上的;爬取是指通过自动化程序从互联网或其他数据源上收集数据的过程具体来说在搜索引擎中的应用搜索引擎中的爬虫程序能够自动地浏览互联网上的网页,并将网页中的文本图片等内容保存到搜索引擎的数据库中这样,当用户通过搜索关键词查找信息时,搜索引擎能够快速地从数据库中检索并展示相关信息,极大;1爬取数据的意思就是通过程序来获取需要的网站上的内容信息,比如文字视频图片等数据2网络爬虫又称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者,是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本另外一些不常使用的名字还有蚂蚁自动索引模拟程序或者蠕。